

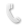

なぜWEBスクレイピング?
今や何でもWEBで情報公開が優先される時代。WEBページからコピー&ペーストで文書を作る方も多いでしょう。でも、大量のWEBページからの手作業は、さすがに何か方法はないか考えたくなります。
WEBスクレイピングは、WEBページの特定の項目から望む形でデータを取り出す手法です。
ただのWEBページのコピーではなく、結果をCSVなどのファイルで取り出せるため、データとしても分かりやすく後加工も容易です。
スクレイピング応用例
・大学などのWEBシラバスを元に、ページレイアウトされたカスタマイズ・シラバスを作成
・学術関連サイトからデータを取り出しまとめ、新たな教材作りに
・政府系サイトで公開されている情報をダム・データとして保存
創文社のWEBスクレイピング その特徴
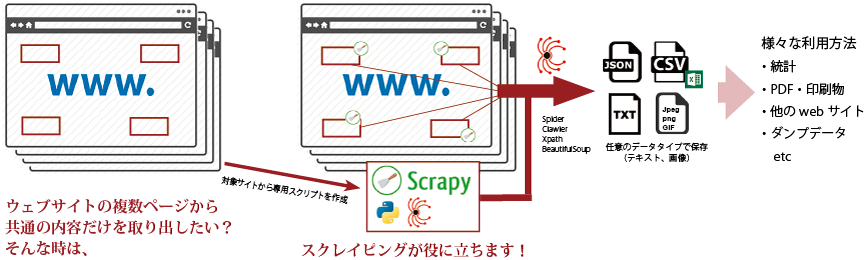
WEBスクレイピングで生成されたデータから、組版処理を通して印刷までワンストップで対応できます。
WEBスクレイピング Q&A
Q WEBスクレイピングって何ですか?A スクレイプとは「削る」という意味がありますが、ネットの世界でスクレイピング scrapingとはデータをかき集める行為を指します。ターゲットとするWEBサイトに対して、予め決めたプログラムに沿ってWEBサイトから必要なデータを取得していく事を指します。
Q 実際どんな風にスクレイピングするのですか?
A 全てソフトウェアで行います。スクレイピングのための専用フレームワークから、スパイダーと呼ばれる巡回ボット、ヘッドレスブラウザ、巡回自動化ツール、javascriptレンダラ、などのマイクロサービスを通して、ターゲットとなるWEBサイトからデータを取得し、スクレイピング・ルールに乗っ取って必要なデータをデータベースに蓄積していきます。蓄積されたデータは、取り出しに必要なクエリとコンバータ・プログラムを通して文書データ、汎用データ形式等で出力されます。
Q スクレイピングされるWEBサイトに影響はないのですか?
A 影響ありません。WEBサイトから見れば、人がウェブサイトを閲覧しているスピードでスクレイピングするので、WEBサーバに負荷を掛けないように配慮してスクレイピングを実行します。
Q 公開されているWEBサイトからデータを勝手に取得するのは違法ではないですか?
A そのWEBサイトがブラウザで表示されているということは、ブラウザがWEBサイトからデータを取得している事と同義です。スクレイピングはブラウザで見える以上の事を行いません。サーバへの違法なハッキング行為とは全く無関係です。
さらに弊社のWEBスクレイピングは、ターゲットとなるWEBサイトのオーナーにスクレイピングの許諾を得る事を条件としています。この条件を満たさない限りスクレイピングを行いません。
Q スクレイピングはWEBサーバのDB等のバックエンドシステムに影響を与えますか?
A スクレイピングは目に見える結果(HTMLデータとイメージなどの実体データ)のみ取得します。バックエンドのシステムには影響を与えません。
Q スクレイピングを実行する環境はどこかのサーバ上ですか?
A 基本的に弊社内のPCから行います。サーバでのデーモン起動ではありません。短いサイクルでスクレイピングを起動させる場合はクラウド等の仮想サーバ上でスクレイピング環境を構築してのデーモン起動も可能です。詳しくはお問合せください。
Q 自分のPCからスクレイピングできるよう、プログラム開発をお願いできますか?
A スクレイピングに必要なサービスのdocker化と関連開発を現在進めています。windowsは、windows10, WSL2, windows用docker desktopがあれば可能です。スパイダーの開発も可能ですが、お客様でのスパイダー・スクリプトの改変は禁止とさせて頂きます。

